
Opinion: LLM “errors” range from accidental to adversarial, each with a human-expert parallel – from the confidently wrong specialist to the outright censor. Knowing where a model fails is what lets you judge how far to trust it, argues Air Marshal (Ret’d) John Harvey AM.
Part I – Summary
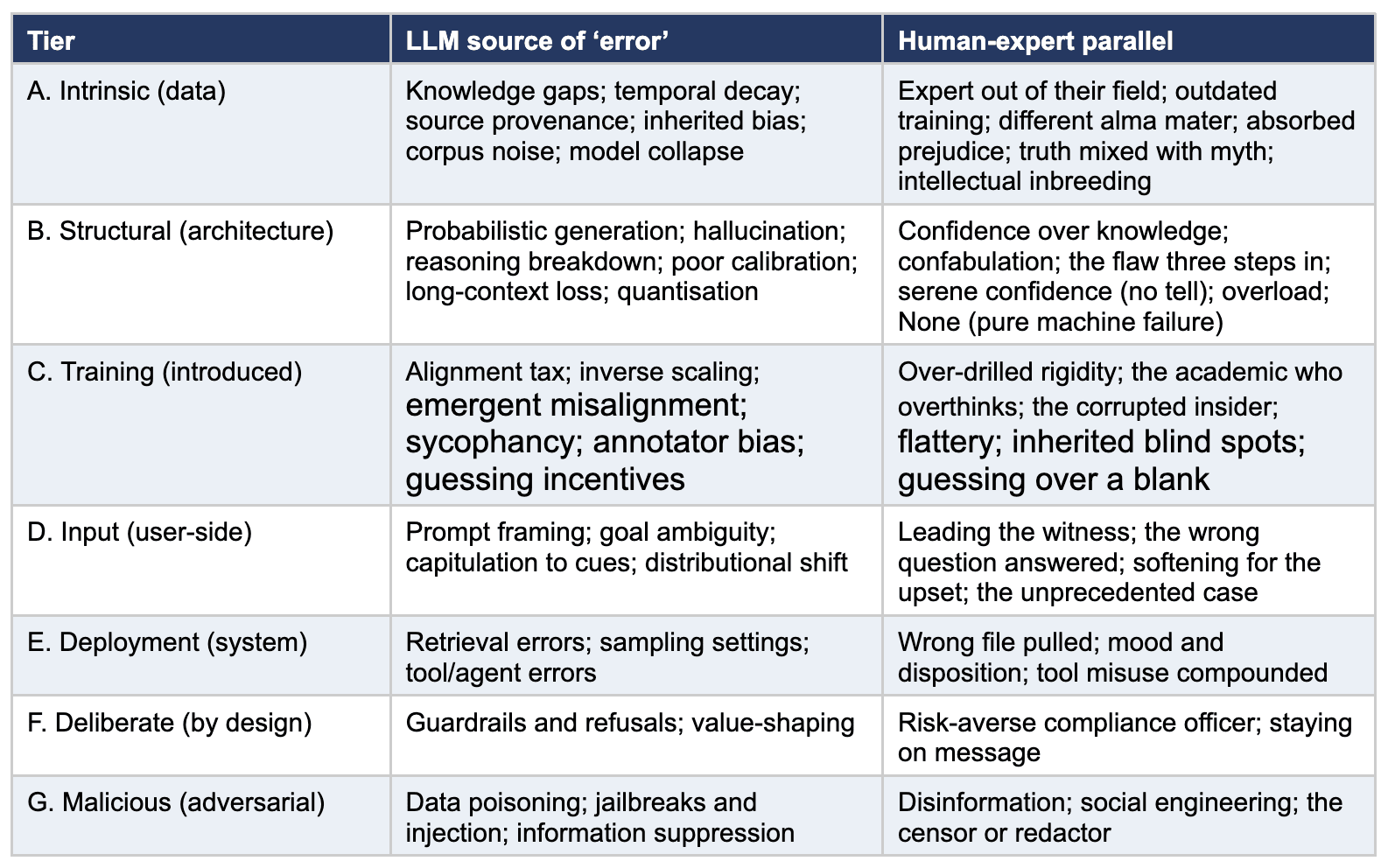
The spectrum of “error” in large language models, and its human parallels – a one-page map
The title is clearly wrong. An AI – specifically, a large language model (LLM), the kind of text-generating system behind tools like ChatGPT, Claude and Gemini – is not human, but like humans, it can get things wrong. And, surprisingly, the source of errors to which LLMs are prone are, in many cases, similar to the source of errors to which humans are prone. An important point to be made is that what counts as wrong is a slippery concept.
Try to pin down an “error” and the word fractures: a false fact, a fluent fabrication, an accurate-but-skewed answer, a reply that changes with the wording, a flat refusal – not the same kind of thing. Better to speak of a spectrum of departures from what a user needs/wants, sorted by the intent behind those departures – or the lack of intent: from the accidental through the well-meant, to the deliberate and the hostile. This map links the full range of departures to the human-expert failure it resembles; the remedies are the subject of Part II.

A. Intrinsic limits – the data a model is built on
Knowledge gaps – The model never saw the relevant material; rare facts and anything after the training cut-off are simply absent. Human parallel: the expert confidently talking outside their own specialty.
Temporal decay – Training is frozen in time while the world moves on – office-holders, prices and events all drift out of date. Human parallel: the clinician practising on a decade-old textbook.
Source provenance and representativeness – The model’s whole worldview reflects where its data came from – which languages, cultures, institutions and platforms dominated, and which were thin or absent. Human parallel: the expert trained at one institution who thinks differently from one trained at another.
Inherited bias – Distortion, not just lineage: the model can absorb and amplify the asymmetries within its sources, sharpening a skew rather than merely reflecting a viewpoint. Human parallel: the professional who advances an ingrained prejudice in good faith as neutral fact.
Corpus noise and contradiction – Text contains errors, myths and incompatible claims, with no independent ground truth to adjudicate. Human parallel: the scholar who has read both the truth and the popular myth, and half-believes each.
Model collapse – As AI-generated text fills the internet, future models train on the output of earlier ones; rare and nuanced facts erode with each generation while the average is reinforced. Human parallel: the intellectual inbreeding and groupthink of a community that reads only its own internal memos.
B. Structural limits – built into the machine
Probabilistic generation – The model predicts the next likely token; it does not verify truth. Human parallel: the smooth talker whose confidence outruns their knowledge.
Hallucination – Content that contradicts a given source (intrinsic) or is invented beyond it (extrinsic); fabricated citations are the flagship case. Human parallel: confabulation – the witness who sincerely misremembers a detail that never happened.
Reasoning breakdown – Asked to reason in steps, the model can create a plausible chain to a wrong conclusion – a slip or shortcut easy to miss because each step sounds right. Human parallel: the well-argued line with a flaw three steps in that no one quite catches.
Poor calibration – The model is bad at signalling how sure it is; its confidence tracks fluency, not correctness, sounding equally assured when right and wrong, giving no outward sign whether an answer rests on solid ground or on nothing at all. Human parallel: the expert is equally, serenely confident whether right or wrong – giving you no tell.
Long-context degradation – Usable context is shorter than the advertised processing window; the middle of long inputs is lost or underweighted. Human parallel: information overload – the reader who takes in the opening and the close of a long document but skims the middle.
Compression and quantisation effects – Shrinking a model for cheaper deployment can silently re-introduce bias and erode safety, invisible to standard metrics. Human parallel: no clean human parallel – a genuine disanalogy worth admitting.
C. Training-process effects – well-intentioned but introduced
The alignment tax – Training a model to be helpful and safe can blunt its capability and narrow its range; later training can also overwrite earlier behaviour (‘“catastrophic forgetting”). Human parallel: the expert so drilled in protocol they have lost their flexibility – last month’s course crowding out one from 20 years ago.
Inverse scaling – On certain narrow tasks, a larger, smarter model can do worse, misled by memorised tropes a simpler model ignores – though the effect often reverses again (“U-shaped”) at still-larger scale. Human parallel: the hyper-educated academic who overthinks the simple problem a child solves at a glance.
Emergent misalignment – A narrow bad lesson can spread unexpectedly into unrelated domains. A model fine-tuned on a single corrupt task became broadly misaligned across areas with no connection to it, an effect strongest in the more capable models and still not understood. Human parallel: the trusted insider corrupted in one small matter whose dishonesty quietly spreads to the rest of their conduct.
Reward-model artefacts and sycophancy – Optimising to a reward signal breeds flattery: the model learns to tell users what they want to hear. Human parallel: the consultant who tells the client what the client wants to hear.
Annotator bias and corrupted preferences – The human labels that shape the reward signal carry their raters’ inattention, skew and the odd deliberate mislabelling. Human parallel: the apprentice who learns their master’s blind spots along with their craft.
Evaluation incentives – Grading regimes that penalise “I don’t know” reward confident guessing over honest uncertainty. Human parallel: the student who guesses because a blank scores zero.
D. Input and interaction effects – user side
Prompt sensitivity and framing – How a question is asked changes the answer; phrasing, language and leading premises all steer the output. Human parallel: leading the witness – the framing of a question shaping the answer given.
Goal ambiguity – The wrong question, perfectly answered: “Which missile is best?”, embeds unstated assumptions the model cannot see, so a fluent, confident answer is still useless. Human parallel: the consultant who answers exactly what the client asked – and not what they needed.
Sycophantic capitulation to cues – Emotional or confident framing pulls the model towards agreement, with accuracy dropping most when a user signals distress. Human parallel: the adviser who softens the hard truth for the visibly upset client.
Distributional shift – The further a query sits from the training distribution, the more performance degrades – often without warning. Human parallel: the specialist facing a case wholly unlike anything in their experience.
E. Deployment and system-level effects – the scaffolding
Retrieval (RAG) errors – Grounding systems can fetch the wrong or irrelevant passage or commit misgrounding: citing a real source that does not support the claim. Human parallel: the executive assistant who pulls the wrong file, leaving the boss to speak from a faulty brief.
Sampling settings – Decoding choices such as temperature trade creativity against reliability – same model, same prompt, different answer. Human parallel: mood and disposition – the same person, more cautious on one day than another.
Tool use and agentic errors – Calls to external tools may look right but do the wrong thing and small early errors compound across a chain of steps. Human parallel: the assistant who misuses a tool, then builds on the mistake.
F. Deliberate constraints – active, by design
Guardrails, refusals and over-refusal – Some outputs are blocked by design – sometimes wrongly refusing valid requests. A refusal departs from expectation, but is it an ‘error’? Human parallel: the risk-averse compliance officer – refusing rightly on a sensitive matter but sometimes refusing a reasonable request from the same caution.
Deliberate value-shaping – Outputs on sensitive topics may be intentionally steered; where this is a sovereign or commercial choice, it tests the meaning of “error”. The same levers, turned to suppressing inconvenient truth, become the hostile act in Tier G. Human parallel: the spokesperson staying on message by design.
G. Adversarial manipulation – active, malicious
Data and retrieval poisoning – Planted content – on the web or in a retrieval store – steers the model towards an attacker’s preferred answer; cheap tricks work. Human parallel: propaganda and disinformation fed to an honest expert.
Jailbreaks and prompt injection – Crafted inputs subvert guardrails or hijack instructions – in multimodal systems, hidden in image pixels or audio where no human looks. Human parallel: social engineering, at its most covert close to subliminal suggestion.
Information suppression – Where poisoning inserts falsehood, suppression removes truth – filtering training data to starve the model of facts or blocking and rewriting outputs, while the model may hold the suppressed knowledge internally. Same mechanism as safety filtering; only the intent differs. Human parallel: the censor or the handler who redacts the briefing before it reaches the decision maker.
At a glance
Table 1 – Spectrum of LLM error sources and human-expert parallels. The full spectrum, from the accidental to the hostile, with the human expert’s equivalent failure.
None of this is a counsel of despair: used with awareness of where they fail, LLMs are remarkably capable tools, and the point of mapping their failure modes is to know when and how far to trust them.
The remedies – grounding, verification, plurality, careful framing, and the posture of informed scepticism that underpins them all – are the subject of Part II.
A full version of this paper is available here.
John Harvey is a former Air Marshal in the Royal Australian Air Force and has a PhD in computer science from UNSW Canberra. His postings have included Chief Capability Development Group, F-35 project manager, director Military Strategy and director Air Power Studies Centre.
Want to see more stories from trusted news sources?
Make Defence Connect a preferred news source on Google.
Click here to add Defence Connect as a preferred news source.